
标题
Factify5wqa:通过问答基于5w方面的事实验证
作者和出处
University of South Carolina, USA(美国南卡罗来纳大学)
摘要
近年来,自动事实核查受到了广泛关注。现代自动事实核查系统主要通过估算可信度来衡量真实性,但这些数值评分不易于理解。与人一样,人类事实核查员通常遵循几个逻辑步骤来验证一个似真主张的真实性,并得出它是真实的还是伪装的结论。流行的事实核查网站对事实分类采用了一种常见的结构,如半真、半假、假、夸张等。因此,有必要建立一个基于方面的可解释系统(指出哪些部分是真实的,哪些部分是错误的),以帮助人类事实核查员提出与事实相关的问题,然后分别验证这些问题以得出最终结论。
在本文中,我们提出了一个基于问题的五 W(谁,什么,何时,哪里,为什么)框架,用于解释事实。为了实现这一目标,我们创建了一个名为 FACTIFY-5WQA 的半自动生成数据集,其中包含 391,041 个事实以及相关的 5W 问题解答,这是本文的主要贡献。我们利用语义角色标注系统定位 5W,通过遮罩语言模型生成主张的 QA 对。之后,我们报告了一个基线 QA 系统,用于从证据文档中自动查找答案,可作为未来该领域研究的基础。最后,我们提出了一种健壮的事实验证系统,该系统接受改写的主张并自动验证它们。数据集和基线模型可在此处获取:https://github.com/ankuranii/acl-5W-QA
引言和结论
社区意识到,由于事实核查的复杂性,它可能无法完全自动化。人机协同是解决这个问题的方法。提出的基于 5W 问题的 fact verification 可能是人类事实核查员的最佳助手。据我们所知,我们是第一个引入基于 5W 问题的 fact verification,并额外提出了相关技术,利用自动方法自动生成 QA,可以立即用于现场的任何新主张。此外,QA 验证部分可以提供证据支持。主张的改写提供了一种全面的事实核查方法。生成的数据集和资源将用于研究目的,包含 391 万项主张。
方法
数据来源和编篡
数据只使用英文。
对文本声明进行转述
不同的新闻出版社的写作风格不同,因此需要转述,将这种不同抹除,以确保开发出基准的健壮性。对不同模型的转述的评估,使用如下三个标准:转述次数,正确度,多样性。候选模型为:Pegasus, T5-Large, GPT-3(text-davinci-003).
转述次数
对于一个候选转述,如果一个转述和声明的MED(最小编辑距离,单位是词)大于 ±2 ,则认为它是一个转述,否则舍弃它。用这种方式评估三个模型中哪个模型生成的转述次数最多。
正确性
用 SNLI 的 SOTA 模型对生成的转述进行评测,留下被标记为蕴含的转述。
多样性
在{声明, 转述}集合中,评测两两之间的相异性,最后取平均。相异性用 BLEU 的倒数来代指。
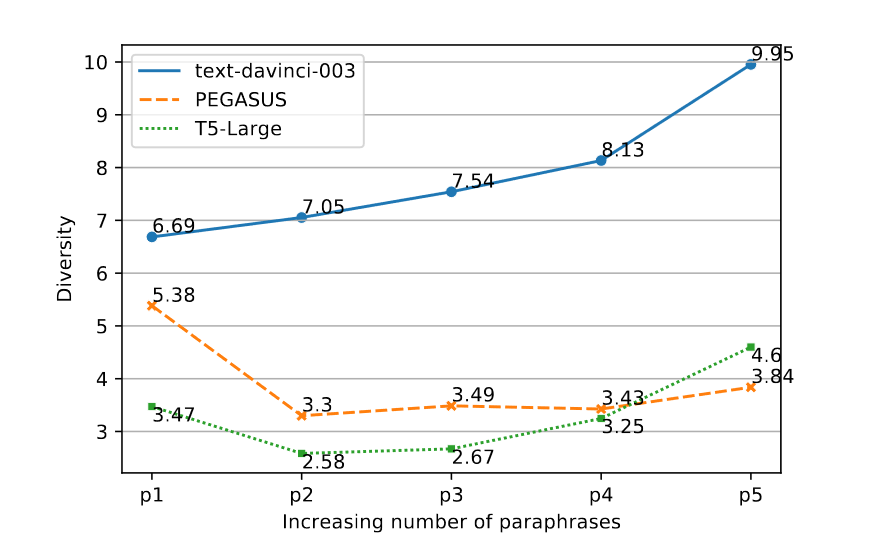
以上实验证明,GPT-3 的效果最好(最大化的语言差异)。
5w 语义角色标注(SRL)

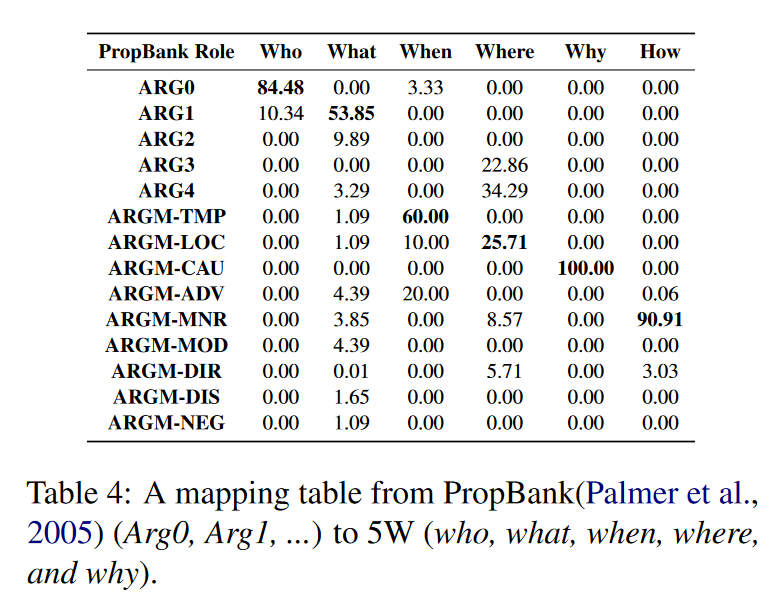
5W(什么,时间, 哪儿, 为什么, 谁) 通常被用来指代为了充分理解一句话所要回答的问题。SRL任务对句子中单词和短语的角色标注可以被看作是来对5W问题做出回答的一种方式。
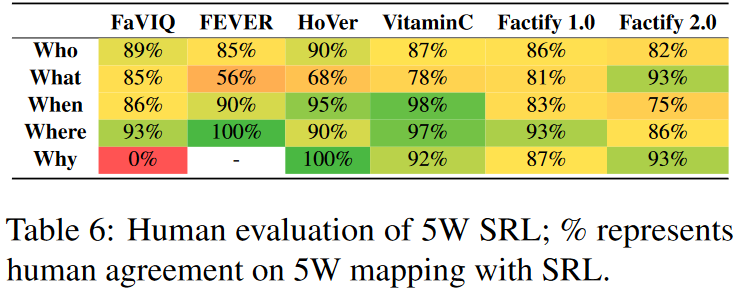
对5W语义角色标注的人类评估
对数据集中的部分数据进行人工标注,结果如下。
基于5w方面的问题对生成
虚假的声明中也会存在一些事实。事实上,大多数假新闻很难被精确检测,因为他们大多是基于正确信息,只是再几个方面偏离了事实。换句话说,声明中的错误信息来自非常具体的不准确的陈述。所以对给定的文本声明,我们通过对给定声明进行语义标注来生成5w问答对。任务现在以生成的问答对为基础。事实验证系统可以提取证据来证实或驳斥声明,这种验证基于问题(什么,时间, 哪儿, 为什么, 谁)。
用 5W SRL 来生成 QA 对,然后分别验证每个方面,这样就可以精确的识别给定声明中哪一个部分是错误的。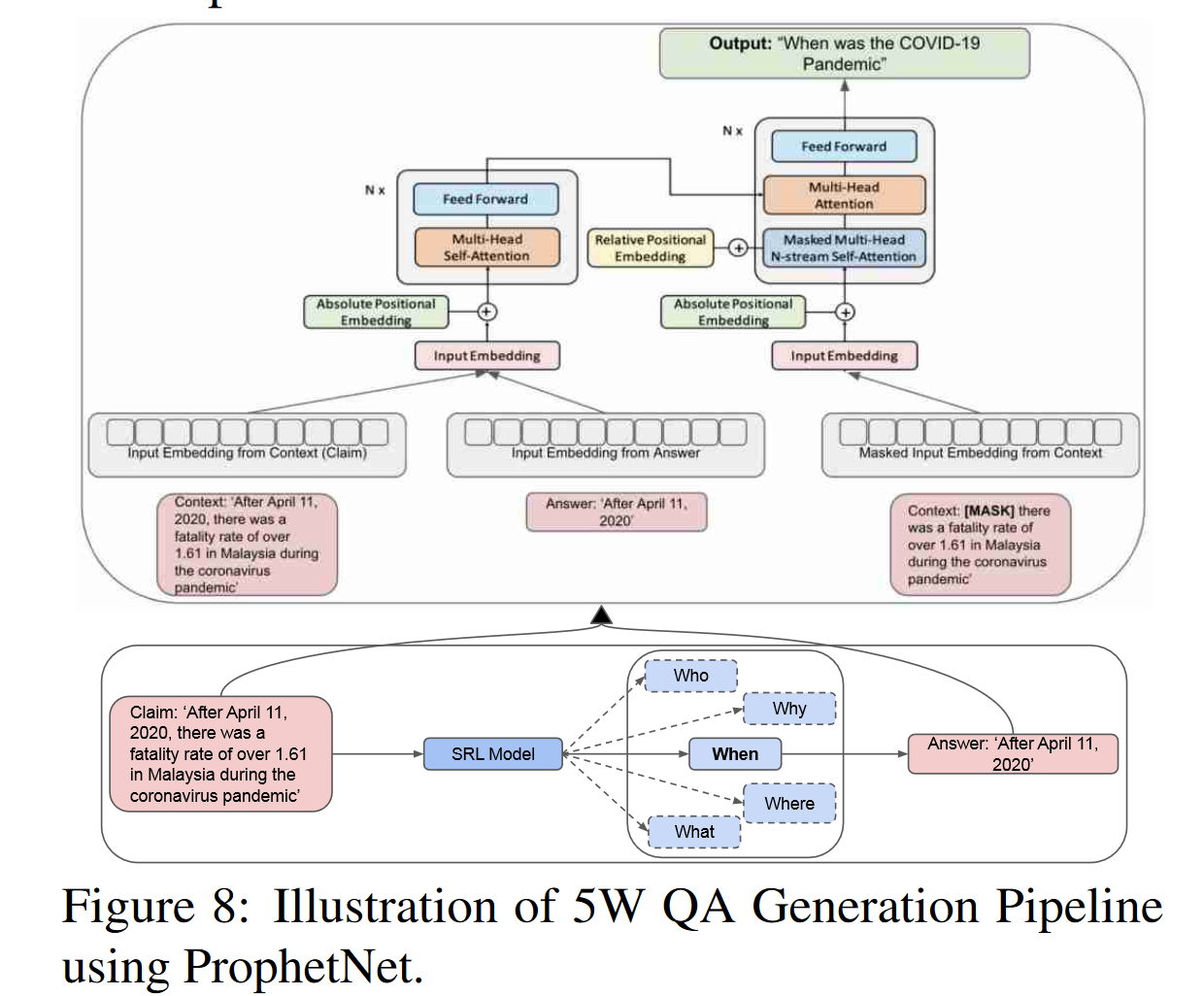
对 5W 问题生成任务,作者使用两个模型做实验:(i) BART (Lewis et al., 2019), and (ii) ProphetNet (Qi et al., 2020) 。发现 ProphetNet 的效果更好。
人类对 QA 生成的评估
随机采样3000组数据,人类评估三个方面:句法是否正确,语义是否正确,抽取的答案是否正确。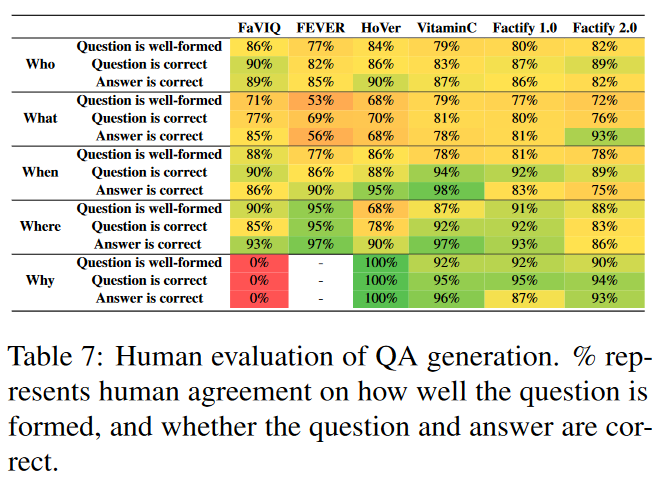
5w 问答验证系统
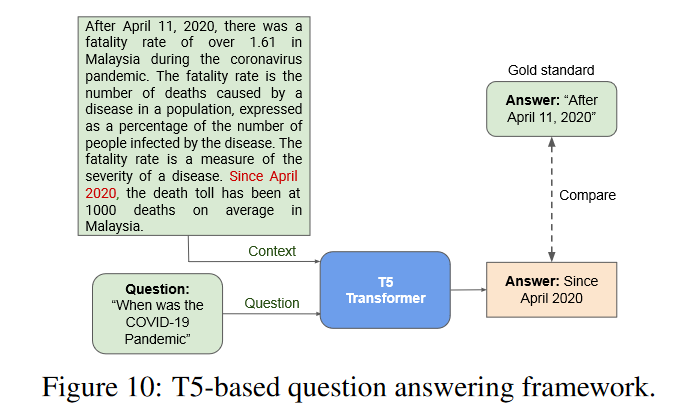 使用 SOTA 问答模型(T5-3B)回答问题。测试了三个模型 T5-3B (Raffel et al., 2020), T5Large (Raffel et al., 2020), and Bert-Large (Devlin et al., 2018)。
使用 SOTA 问答模型(T5-3B)回答问题。测试了三个模型 T5-3B (Raffel et al., 2020), T5Large (Raffel et al., 2020), and Bert-Large (Devlin et al., 2018)。
挑选最佳的 5w 问题生成模型和 5w问题验证模型
两个系统成对测试,最终发现最佳组合是T5-3B 和 ProphetNet。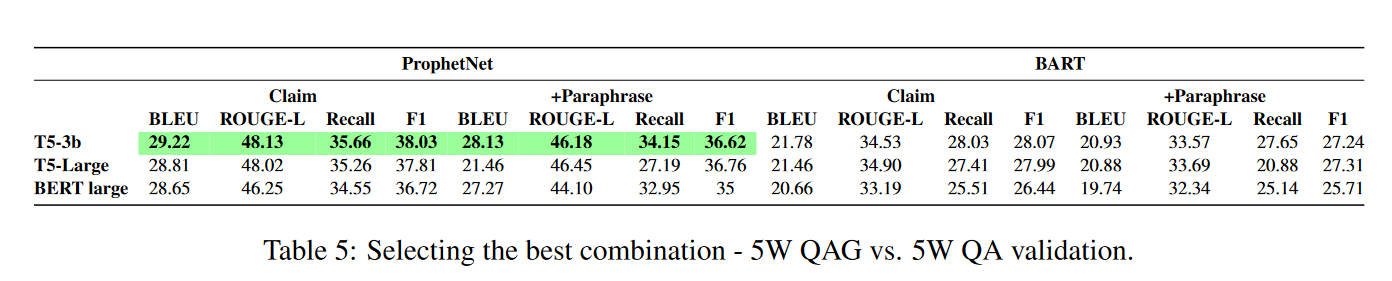
个人感悟
工作量真的很大。